머신러닝 공부 - K-최근접 이웃(K-Nearest Neighbor) 쉽게 이해하기
K-최근접 이웃(K-Nearest Neighbor)은 머신러닝에서 사용되는 분류(Classification) 알고리즘이다. 유사한 특성을 가진 데이터는 유사한 범주에 속하는 경향이 있다는 가정하에 사용한다.
K-최근접 이웃 알고리즘의 개념
원리를 쉽게 이해하기 위해 아래 그림을 보자. 녹색 점을 파란 사각형으로 혹은 빨간 삼각형으로 분류할지 결정하는 문제다.
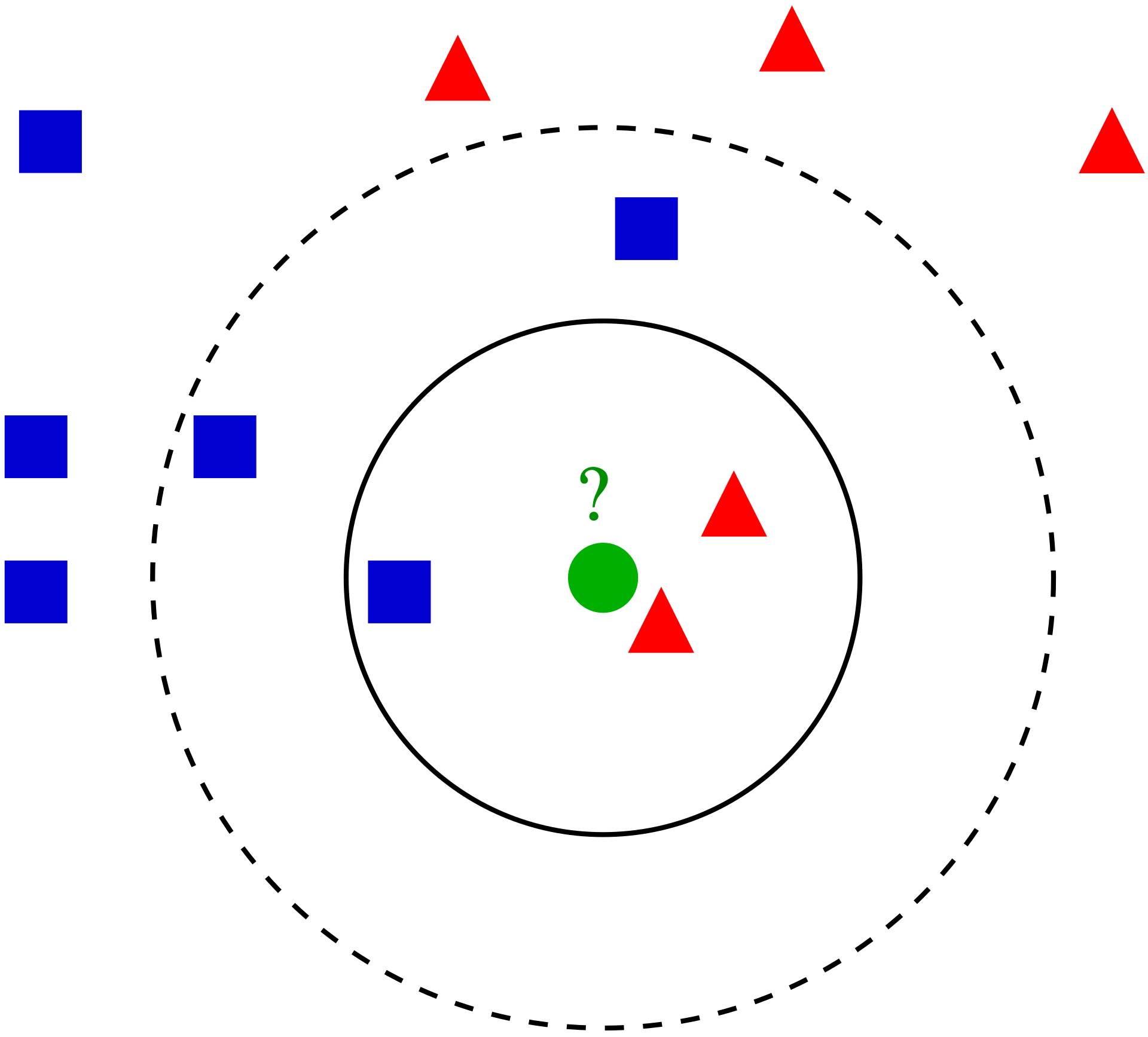
- 가장 가까운 이웃의 수 k를 3으로 설정하면 실선 원의 범위를 고려하게 되는데, 이 때 빨간색 삼각형이 우세하므로 초록점은 빨간 삼각형으로 분류된다.
- 가장 가까운 이웃의 수 k를 5로 설정하면 점선 원의 범위를 고려하게 되고, 이 경우에는 파란색 사각형이 많으므로 초록점은 파란 사각형으로 분류된다.
일종의 다수결이다.
k를 짝수로 설정할 때는 동률(tie)이 나올 수가 있는데, 이를 처리하는 몇가지 방법이 있긴 하다. 예를 들면 가장 가까운 이웃을 따른다든가, 아니면 랜덤으로 찍는다든가. 그러나 데이터가 충분하면 어쨌든 이러나 저러나 결과는 비슷하게 나오니 너무 걱정 말자.
아무튼 다수결이 K-Nearest Neighbor 알고리즘의 핵심 개념이다. 이미 각 점들의 분류를 알고 있으면 새로운 점이 등장했을 때 그 녀석을 어디로 분류할지 정할 수 있는 거다.
그런데 이 알고리즘에는 몇가지 생각해볼 문제들이 있다.
1. 정규화(Normalization)
위 예제에서는 x와 y값이 적당히 잘 퍼져 있으니 문제가 안 드러나지만 실제 데이터는 그렇지 않다. 예를 들어 성인 남녀의 연봉과 시력을 특성(feature)으로 생각해보자. 연봉 단위가 원이면 편차가 천만 단위를 넘어가겠지만, 시력은 소숫점까지 따져가며 최대값과 최소값의 편차가 10 미만일 거다. 아무튼 그렇게 스케일이 다른 데이터를 같은 기준으로 계산하면 연봉이 압도적으로 반영되기 때문에 터무니 없는 결론이 나올 수 있다.
그래서 K-Nearest Neighbor 알고리즘을 사용할 때는 모든 특성들을 모두 고르게 반영하기 위한 정규화(Noramlizaion)를 한다. 정규화하는 방법에는 여러가지가 있는데, 가장 널리 사용되는 방법은 두 가지다.
- Min-Max Normalization (최소-최대 정규화) : 최소값을 0, 최대값을 1로 고정한 뒤 모든 값들을 0과 1사이 값으로 변환하는 방법
- Z-Score Normalization (Z-점수 정규화) : 평균과 표준편차를 활용해서 평균으로부터 얼마나 떨어져 있는지 z-점수로 변환하는 방법
이 외에 다른 방법들도 있고, 각각의 장단점이 있지만 아무튼 보통 위 방법을 적절히 사용해서 특성들을 정규화 해주면 어느정도는 해결된다.
2. K 개수 선택
또 다시 고려할 중요한 문제는 “k를 몇으로 정할 것인가”이다. 이건 모든 값을 실제로 테스트하면서 분류 정확도(Accuracy)를 계산하는 과정에서 단서를 찾을 수 있다.
k가 너무 작을 때 : Overfitting
일단 k가 너무 작은 경우를 생각해보자. 극단적으로 k=1이라고 하자. 그러면 분류 정확도가 상당히 낮을 수밖에 없다. 시야가 좁아지는 거고, 아주 근처에 있는 점 하나에 민감하게 영향을 받기 때문이다. 이를 overfitting(과적합)이라고 한다.
K-Nearest Neighbors 알고리즘에서는 주변 다른 이웃들까지 충분히 고려하지 않았을 때 오버피팅이 발생한다. 그래서 이상치(outlier)가 있을 경우 근처에 있는 점의 레이블이 그 이상치에 의해 결정되어 버릴 수 있다.
k가 너무 클 때 : Underfitting
반면에 k가 너무 큰 경우에는 underfitting(과소적합)이 발생한다. underfitting은 분류기가 학습 세트의 세세한 부분에 충분히 주의를 기울이지 않았기 때문에 나타난다. 예를 들어 학습 세트에 100개의 점이 있고 k=100으로 설정했다고 극단적으로 가정해보자. 그러면 모든 점이 결국 동일한 방식으로 분류될 거다. 점 사이의 거리는 의미가 없어진다. 물론 이건 극단적인 예이지만 아무튼 k가 너무 그면 분류기가 학습 데이터를 충분히 세세하게 살펴보지 못한다는 뜻이다.
분류 모델을 생성할 때 일부 데이터는 검증에 활용되도록 떼어놓고 학습 데이터로만 모델을 생성해서 검증 데이터를 넣어 분류 정확도(Accuray) 확인할 수 있는데, 아래 그래프는 한 분류 모델에서 k 값을 변화시키면서 정확도를 확인한 예시다.

너무 k가 작으면 과적합이 발생하여 정확도가 상대적으로 낮다. 반면 k가 너무 커져도 언더 피팅이 발생해서 정확도가 떨어지기 시작하는 걸 알 수 있다. 결국 75 언저리에서 가장 높은 정확도를 보여준다.
핵심 요약
K-최근접 이웃(K-Nearest Neighbor) 알고리즘의 핵심 내용을 요약해보면 아래와 같이 정리할 수 있다.
- n개의 특성(feature)을 가진 데이터는 n차원의 공간에 점으로 개념화 할 수 있다.
- 유사한 특성을 가진 데이터들끼리는 거리가 가깝다. 그리고 거리 공식을 사용하여 데이터 사이의 거리를 구할 수 있다.
- 분류를 알 수 없는 데이터에 대해 가장 가까운 이웃 k개의 분류를 확인하여 다수결을 할 수 있다.
- 분류기의 효과를 높이기 위해 파라미터를 조정할 수 있다. K-Nearest Neighbors의 경우 k 값을 변경할 수 있다.
- 분류기가 부적절하게 학습되면 overfitting 또는 underfitting이 나타날 수 있다. K-Nearest Neighbors의 경우 너무 작은 k는 overfitting, 너무 큰 k는 underfitting을 야기한다.