머신러닝 공부 - 선형회귀(Linear Regression) 쉽게 이해하기
본 포스팅에서는 머신러닝에서 사용할 선형 회귀 분석에 대한 개념 설명을 누구나 이해할 수 있을 정도의 수준으로 가볍게 소개한다.
선형 회귀란 무엇인가
머신 러닝의 가장 큰 목적은 실제 데이터를 바탕으로 모델을 생성해서 만약 다른 입력 값을 넣었을 때 발생할 아웃풋을 예측하는 데에 있다.
이때 우리가 찾아낼 수 있는 가장 직관적이고 간단한 모델은 선(line)이다. 그래서 데이터를 놓고 그걸 가장 잘 설명할 수 있는 선을 찾는 분석하는 방법을 선형 회귀(Linear Regression) 분석이라 부른다.
예를 들어 키와 몸무게 데이터를 펼쳐 놓고 그것들을 가장 잘 설명할 수 있는 선을 하나 잘 그어놓게 되면, 특정 인의 키를 바탕으로 몸무게를 예측할 수 있다.

이 선은 당연히 근사치다. 정확하지 않을 거다. 그래도 어쨌든 최대한 가깝게 추정할 수 있다는 데에 의의가 있는 거 아닌가. 세상에 완벽하고 정확한 건 없다. 데이터 분석이고 통계고 다 최선을 다해 뭔가를 해보려는 노력의 일환이니까. 아무튼.
아마 중학교 수학 시간에 직선 그래프를 그리는 1차 함수에 대해 배운다. 아마 아래와 같은 식으로 나타냈을 거다.
y = mx + b
기울기 m, 절편 b에 따라 그 선의 모양이 정해지기 때문에 x를 넣었을 때 y를 구할 수 있다. 선형 회귀 분석의 목적도 결국 우리가 가진 데이터를 가장 잘 설명할 수 있는 최고의(?) m과 b를 얻는 거다.
선형 회귀에서 발생하는 오차, 손실 (Loss)
데이터들을 놓고 선을 긋는다는 건… 결국 대충 어림잡아본다는 뜻인데, 그러면 당연히 선은 실제 데이터와 약간의 차이가 발생한다. 일종의 오차라 할 수 있는데, 앞으로는 손실(Loss)이라고 부르자.
아래 그림을 보면 초록색 선의 길이가 손실이 된다.
그런데 엄밀히 보면 + 혹은 – 방향을 고려하지 않고 얘기한 거다. 선과 실제 데이터 사이에 얼마나 오차가 있는지 구하려면 양수, 음수 관계 없이 동일하게 반영되도록 모든 손실에 제곱을 해주는 게 좋다.
그리고 이런 방식으로 손실을 구하는 걸 평균 제곱 오차(mean squared error, 이하 MSE)라고 부른다. 손실을 구할 때 가장 널리 쓰이는 방법이다.
손실을 구하는 이 외의 방법으로는 MSE처럼 제곱하지 않고 그냥 절대값으로만 바로 평균을 구하는 평균 절대 오차(mean absolute error, 이하 MAE), MSE와 MAE를 절충한 후버 손실(Huber loss), 1−MSE/VAR으로 구하는 결정 계수(coefficient of determination) 등이 있다.
일단 너무 깊게 가진 말자.
아무튼 결국 선형 회귀 모델의 목표는 모든 데이터로부터 나타나는 오차의 평균을 최소화할 수 있는 최적의 기울기와 절편을 찾는 거다.
손실을 최소화 하기 위한 방법, 경사하강법(Gradient Descent)
머신러닝에서 사용하는 모형은 (우리가 중고등학교 때 수학 시간에 배운 단순한 방정식으로는 설명할 수 없을 만큼) 매우 복잡하기 때문에 선형 회귀 분석에서도 최적의 기울기와 절편을 구할 수 있는 마땅한 방법이 없다.
그런데 그나마 단서가 있다면 위에서 설명한 손실(Loss)을 함수로 나타내면 이렇게 아래로 볼록한 모양이라는 거다.

그래서 일단 파라미터를 임의로 정한 다음에 조금씩 변화시켜가며 손실을 점점 줄여가는 방법으로 최적의 파라미터를 찾아간다. 그리고 이런 방법을 경사하강법(Gradient Descent)이라 부른다.
그리고 이 때 미분이 사용되는데 당연히 직접 할 필요 없으니 걱정할 필요 없다. 지금은 일단 개념만 이해하고 넘어가자.
수렴 (Convergence)
아무튼 선형 회귀 분석을 수행하면 기울기와 절편을 계속 변경해가면서 최적의 값을 찾게 될 텐데, 이걸 언제까지 할지 정해줘야 한다. 무작정 계속 시킬 수는 없으니까.
어차피 파라미터를 계속 조정 하다보면 어느정도 최적의 값으로 수렴(converge)하고, 그 이상 시도하는 건 별로 의미가 없어진다.
그렇다면 이걸 우리가 어떻게 결정할까? 어차피 머신러닝 알고리즘이 알아서 잘 수렴할 거니 걱정 말자.
학습률 (Learning Rate)
다만 우리는 학습률(Learning Rate)이라는 걸 정해줄 필요가 있다. 얼마나 꼼꼼하게 학습할지 결정하는 거다.
아래 그림은 학습률이 너무 작을 때, 그리고 너무 클 때 생기는 문제를 표현하고 있다.
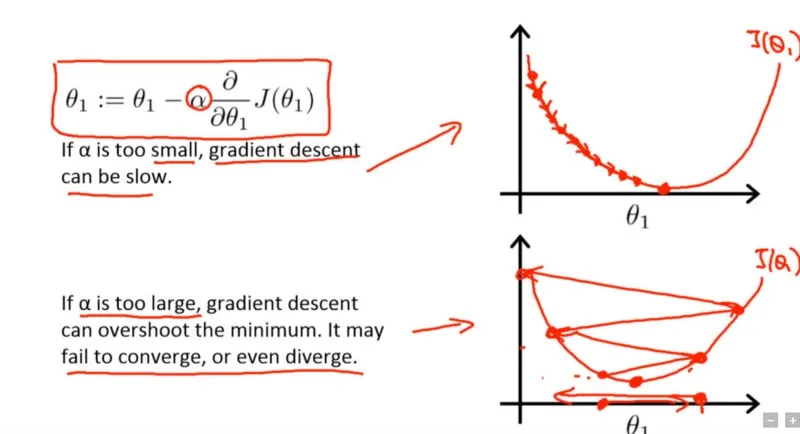
학습률을 작게 설정하면 최적의 값으로 수렴할 때까지 시간이 오래 걸린다.
그렇다고 학습률을 크게 설정하면 최적의 값을 제대로 찾지 못한다. 일을 대충하는 거다. 대신 일을 빨리 하긴 하겠지.
그래서 모델을 학습시킬 때는 최적의 학습률을 찾는 게 중요하다. 효율적으로 파라미터를 조정하면서도 결국 최적의 값을 찾아 수렴할 수 있을 수준으로.
일단 여기까지가 선형회귀 개념에 대한 소개가 되겠다.