머신러닝 공부 - 정규화(Normalization) 쉽게 이해하기
왜 정규화를 해야 하는가
머신러닝 알고리즘은 데이터가 가진 feature(특성)들을 비교하여 데이터의 패턴을 찾는다.
그런데 여기서 주의해야 할 점이 있다. 데이터가 가진 feature의 스케일이 심하게 차이가 나는 경우 문제가 되기 때문이다.
예를 들어 ‘주택’에 관한 정보가 담긴 데이터를 생각해보자. 그 안에 feature로 방의 개수(개), 얼마나 오래 전에 지어졌는지(년) 같은 것들이 포함될 수 있을 거다. 그리고 여기서 머신러닝 알고리즘을 통해 어느 집이 가장 적합한지 예측을 시도한다고 해보자. 그러면 각 데이터 포인트를 비교할 때 더 큰 스케일을 가진 feature, 즉 얼마나 오래 전에 지어졌는지(년)에 따라 그 데이터가 완전히 좌지우지 되는 꼴이다.
아래 그림을 보면 이해가 쉬울 것 같다.
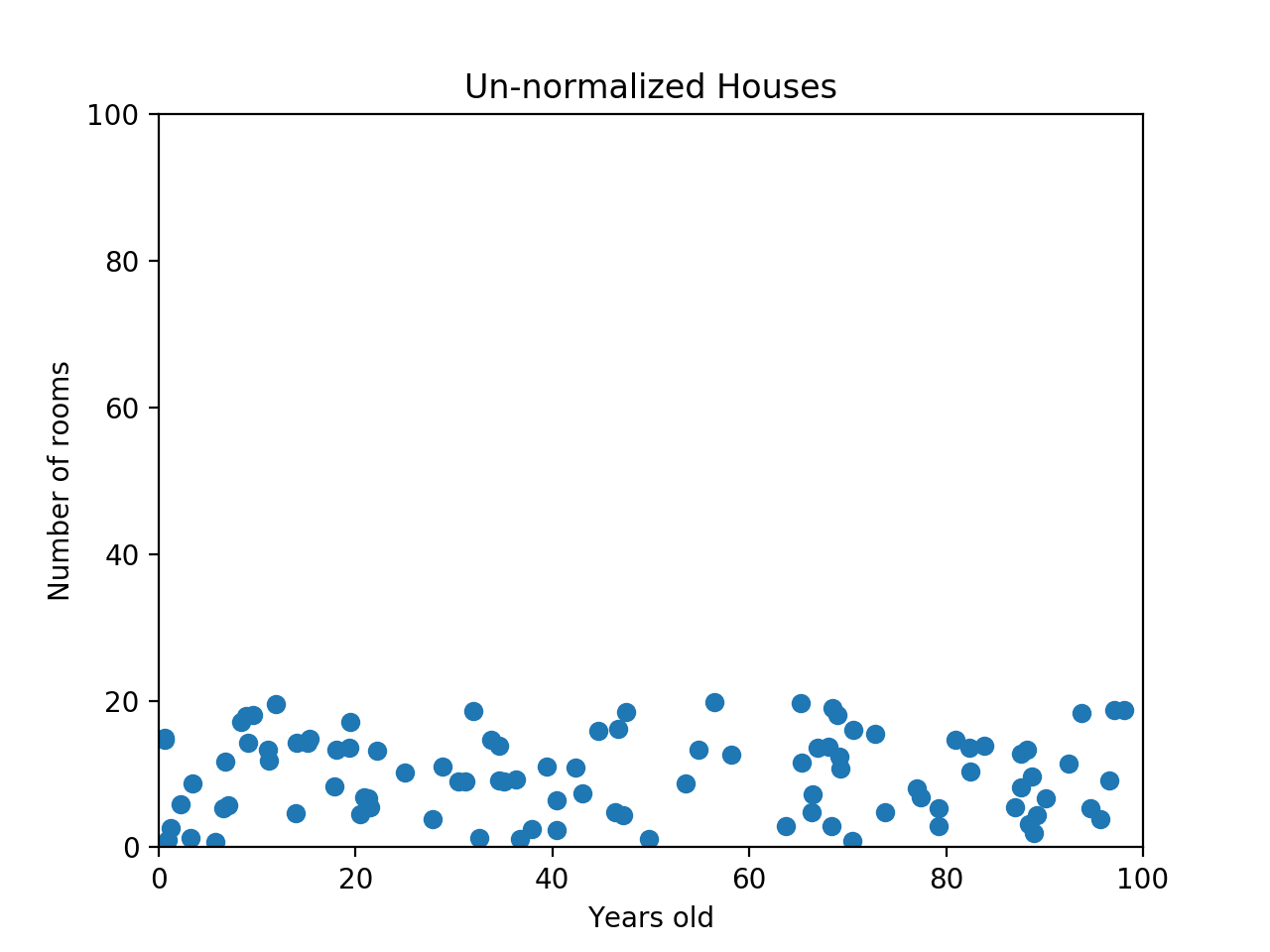
우리는 머신러닝 알고리즘이 방 1개만 있는 집과 20개짜리 집이 얼마나 큰 차이가 나는지 인식하기를 기대한다. (상식적으로 그렇지 않은가.)
그런데 그림에서도 알 수 있듯이 만약 두 집이 비슷한 시기에 지어졌을 경우 두 데이터 포인트가 매우 가깝게 위치하게 된다. 방 개수 같은 건 별로 중요한 요소가 아니게 되는 거다.
그래서 모든 데이터 포인트가 동일한 정도의 스케일(중요도)로 반영되도록 해주는 게 정규화(Normalization)의 목표다.
만약 위 데이터를 MIN-MAX 정규화하면 (정규화 방법은 아래에 이어서 설명하겠다.) 아래와 같이 나타난다.
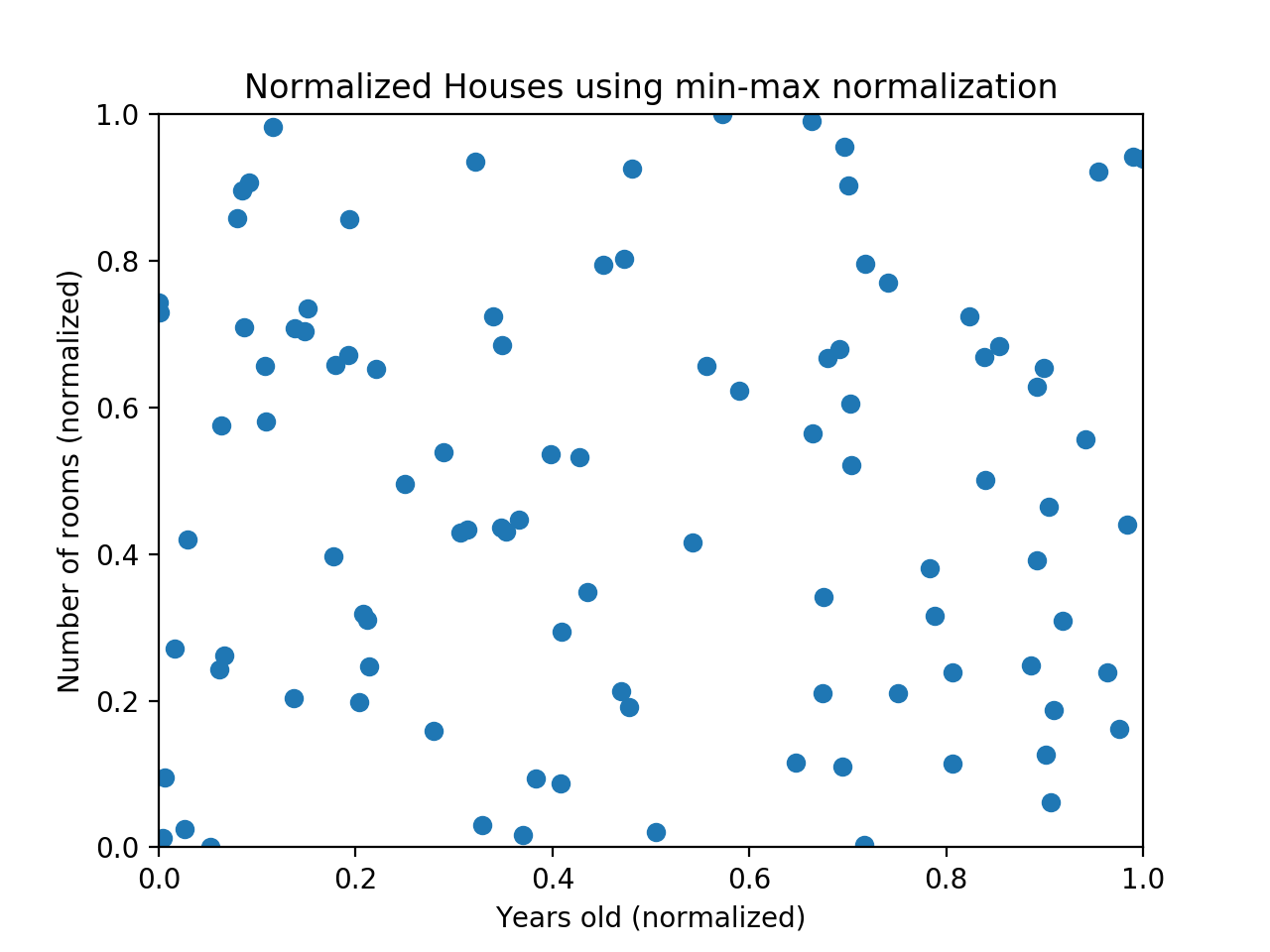
데이터를 정규화 하는 두 가지 방법
이외에도 다른 정규화 방법이 있겠으나 일단 일반적으로 가장 널리 사용되는 방법은 아래 두 가지다.
- Min-Max Normalization (최소-최대 정규화)
- Z-Score Normalization (Z-점수 정규화)
각각의 장단점이 있기 때문에 정확히 이해하고 언제 어떤 방식으로 정규화를 할지 결정할 수 있어야 한다.
하나씩 알아보자.
1. Min-Max Normalization (최소-최대 정규화)
최소-최대 정규화는 데이터를 정규화하는 가장 일반적인 방법이다. 모든 feature에 대해 각각의 최소값 0, 최대값 1로, 그리고 다른 값들은 0과 1 사이의 값으로 변환하는 거다.
예를 들어 어떤 특성의 최소값이 20이고 최대값이 40인 경우, 30은 딱 중간이므로 0.5로 변환된다.
만약 X라는 값에 대해 최소-최대 정규화를 한다면 아래와 같은 수식을 사용할 수 있다.
1
(X - MIN) / (MAX-MIN)
리스트에 포함된 값들을 모두 최소-최대 정규화 하는 방법을 파이썬의 함수로 작성하면 이렇게 될 거다.
1
2
3
4
5
6
7
8
def min_max_normalize(lst):
normalized = []
for value in lst:
normalized_num = (value - min(lst)) / (max(lst) - min(lst))
normalized.append(normalized_num)
return normalized
그런데 최소-최대 정규화에는 치명적인 단점이 있다. 이상치(outlier)에 너무 많은 영향을 받는다는 거다.
예를 들어, 100개의 값이 있는데 그 중 99개는 0과 40 사이에 있고, 나머지 하나가 100이면 어떨까. 그러면 99개의 값이 모두 0부터 0.4 사이의 값으로 변환된다.
그림으로 나타내면 아래와 같다.
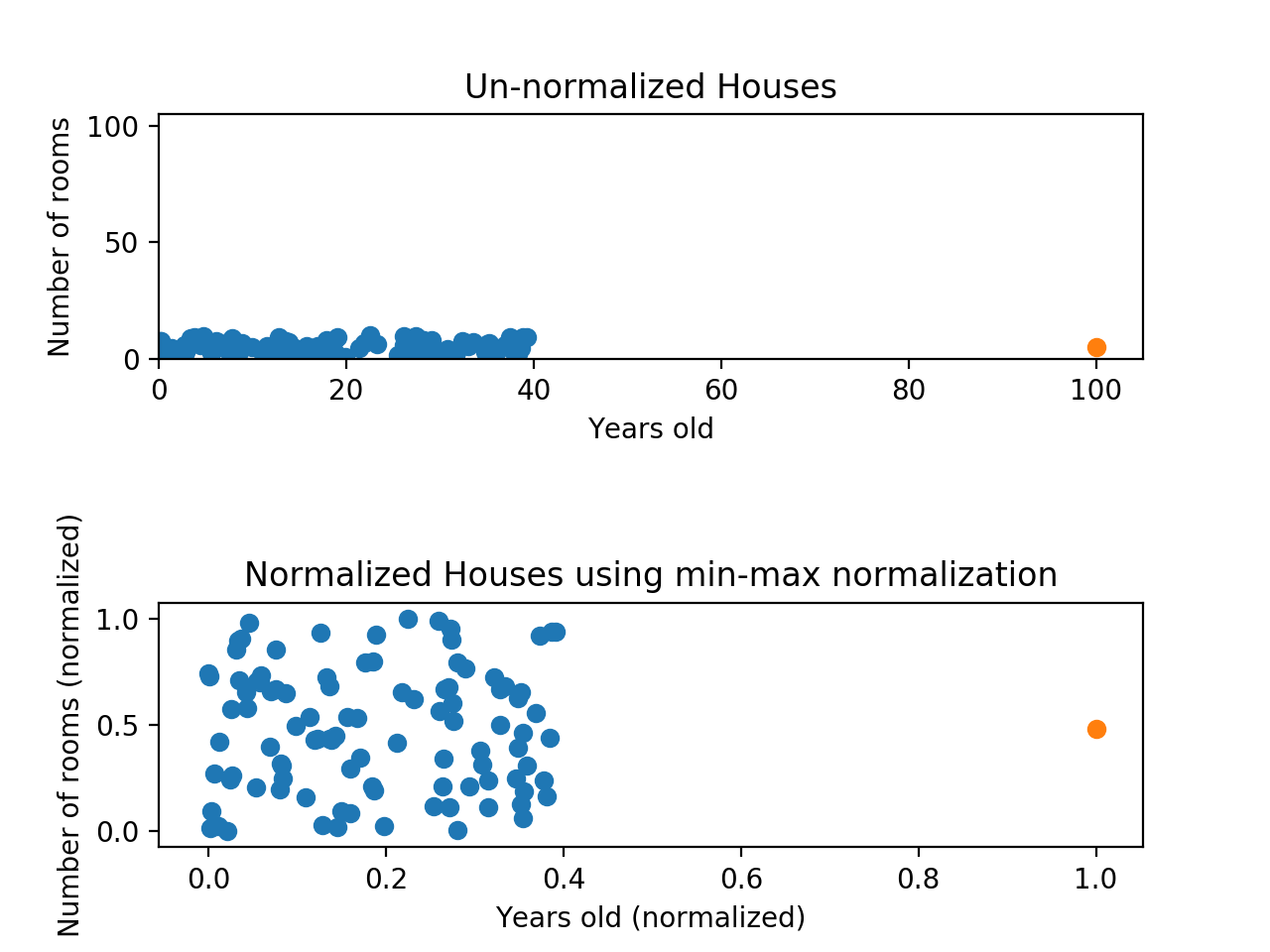
위 그림을 보면 y축에서는 정규화가 효과적으로 적용되었으나 x축에서는 여전히 문제가 있다. 이 상태로 데이터의 점들을 비교한다면, y축의 영향이 지배적일 수밖에 없다.
이러한 단점을 보완하려면 Z-점수 정규화를 고려해봐야 한다.
2. Z-Score Normalization (Z-점수 정규화)
Z-점수 정규화는 이상치(outlier) 문제를 피하는 데이터 정규화 전략이다.
X라는 값을 Z-점수로 바꿔주는 식은 아래와 같다. (사실 고등학교 수학 시간에 정규분포, 표준점수 등의 개념으로 다루는 내용이다.)
1
(X - 평균) / 표준편차
만약 feature의 값이 평균과 일치하면 0으로 정규화되겠지만, 평균보다 작으면 음수, 평균보다 크면 양수로 나타난다. 이 때 계산되는 음수와 양수의 크기는 그 feature의 표준편차에 의해 결정되는 거다. 그래서 만약 데이터의 표준편차가 크면(값이 넓게 퍼져있으면) 정규화되는 값이 0에 가까워진다.
리스트에 포함된 값들을 모두 Z-점수로 정규화 하는 방법을 파이썬의 함수로 작성하면 이렇게 될 거다.
1
2
3
4
5
6
7
8
def z_score_normalize(lst):
normalized = []
for value in lst:
normalized_num = (value - np.mean(lst)) / np.std(lst)
normalized.append(normalized_num)
return normalized
아래 그림을 보자. 최대-최소 정규화에서 예로 들었던 데이터이지만, 이번엔 Z-점수 정규화를 사용해본 거다.
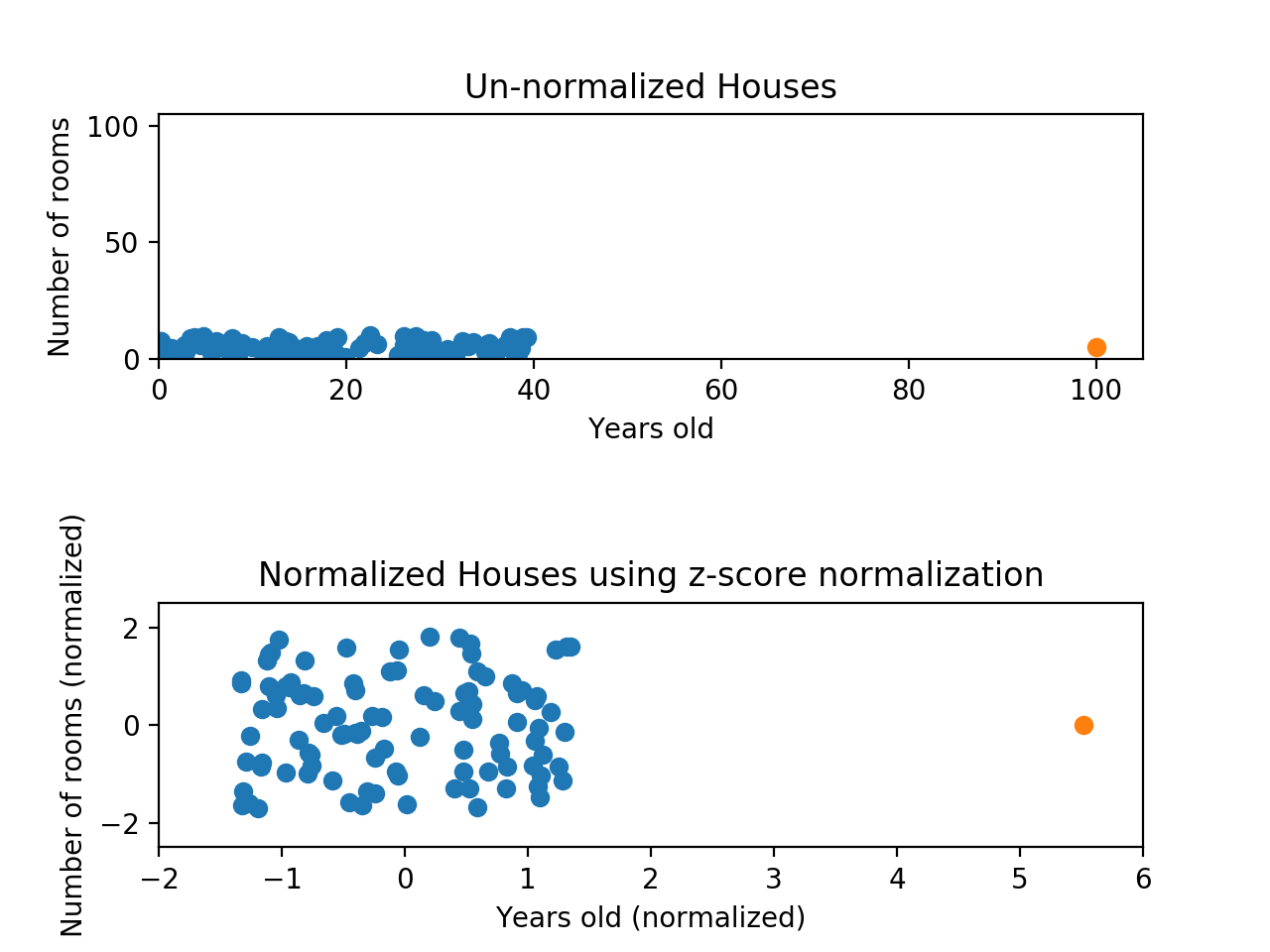
데이터가 여전히 찌그러져 보이긴 하지만, 그래도 거의 모든 점들이 x축과 y축에서 -2와 2 사이에 있다. 이제 어느정도 비슷한 스케일로 나타낸 셈이다. 여전히 x축에 5가 넘는 녀석 하나가 있어서 정확히 동일하진 않지만, 그래도 최소-최대 정규화에서 나타난 문제는 해결했다고 볼 수 있다.
요약
데이터 정규화는 머신러닝에서 꼭 알아야 하는 개념이다. 매우 훌륭한 데이터를 가지고도 정규화를 놓치면 특정 feature가 다른 feature들을 완전히 지배할 수 있기 때문이다. 거의 모든 정보를 버리는 꼴이니까! 어쨌든 정규화는 아래 두 가지 방법을 적절히 사용해자.
- 최소 최대 정규화: 모든 feature들의 스케일이 동일하지만, 이상치(outlier)를 잘 처리하지 못한다.
- Z-점수 정규화 : 이상치(outlier)를 잘 처리하지만, 정확히 동일한 척도로 정규화 된 데이터를 생성하지는 않는다.