머신러닝 공부 - Bag-of-Words(BoW) 쉽게 이해하기
자연어 처리(NLP: Natural Language Processing), 흔히 말하는 텍스트 마이닝을 할 때 Bag-of-Words(이하 BoW)는 정말 단순하지만 여전히 유효한 모델이다. 여러가지 장면에 쉽게 활용할 수 있기 때문이다. 예를 들면 글에서 키워드를 뽑아낸다거나 스팸 메일을 필터링 한다거나, 긍정 vs 부정과 같은 감성 분석을 하는 등.
본 포스팅에서는 Bow에 대해 누구나 쉽게 이해할 수 있는 수준으로 소개해보고자 한다.
BoW(Bag-of-Words)의 개념
애초에 컴퓨터는 인간이 아니기 때문에 언어를 이해할 방법이 없다고 봐도 된다. 그래서 어떤 식으로든 1과 0 밖에 모르는 컴퓨터가 인간의 언어 사용 패턴을 최대한 이해하도록 여러가지 방법을 강구해야 하는데, 흔히 사용되는 방법이 통계적 언어 모델(SLM: Statistical Language Model)이다.
통계적 언어 모델은 컴퓨터가 ‘확률 분포’를 기반으로 언어를 이해하도록 하는 방법론이고, 이외에도 신경망 언어 모델(NNLM: Neural Network Language Model) 같은 개념이 있는데 일단 어려우니 넘어가자.
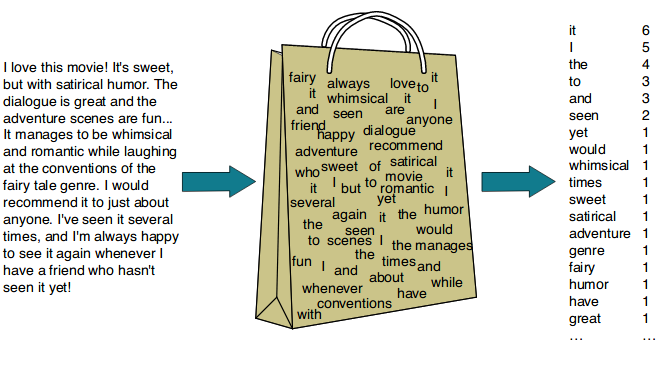
아무튼 BoW는 어휘의 빈도(개수)에 대해 통계적 언어 모델을 적용해서 나타낸 것이라 이해하면 된다. 대단한 게 아니다. 그냥 등장하는 단어들의 숫자를 세서 그걸 가지고 뭔가를 하는 거다.
 )
)
그래서 이름도 Bag-of-Words인 거다. 단어 주머니.
그래서 실제로 분석이나 활용을 할 때 단어 사전을 만들어놓은 후에 문서(텍스트)가 있으면 그걸 벡터로 바꿔준다.(vectorization)
문서-단어 행렬(Document-Term matrix)
문서-단어 행렬(Document-Term Matrix)은 어떤 문서에서 등장하는 각 단어들의 빈도를 나타낸 행렬이다. BoW와 별개의 개념이 아니라 Bow를 실제로 활용하기 위해 행렬의 형식으로 표현한 거라 생각하면 된다.
예를 들어보자.
만약 [“가지”, “감자”, “고구마”, “당근”, “무”, “미역”, “양파”, “피망”]이라는, 식재료 단어 사전를 가지고 있을 때 "감자 감자 감자 감자 감자 당근 미역 미역 미역 피망 피망"이라는 문서가 주어진다면 Bow 개념을 적용해서 아래와 같은 문서-단어 행렬로 나타낼 수 있을 거다.
1
{"가지":0, "감자":5, "고구마":0, "당근":1, "무":0, "미역":3, "양파":0, "피망":2}
보다시피 단어 순서에는 관심이 없고, 그냥 숫자만 센다.
그래서 문서가 여러개 있을 때는 아래와 같은 행렬로 나타낼 수 있을 거다.
| 가지 | 감자 | 고구마 | 당근 | 무 | 미역 | 양파 | 피망 | |
|---|---|---|---|---|---|---|---|---|
| 문서0 | 12 | 10 | 3 | 8 | 6 | 3 | 4 | 12 |
| 문서1 | 13 | 1 | 4 | 10 | 1 | 6 | 3 | 1 |
| 문서2 | 1 | 4 | 8 | 8 | 13 | 4 | 2 | 12 |
| 문서3 | 3 | 15 | 9 | 11 | 11 | 3 | 11 | 2 |
| 문서4 | 10 | 11 | 7 | 14 | 5 | 12 | 0 | 8 |
| 문서5 | 1 | 2 | 1 | 15 | 3 | 3 | 9 | 3 |
| 문서6 | 15 | 10 | 12 | 11 | 5 | 2 | 3 | 10 |
| 문서7 | 7 | 8 | 13 | 7 | 9 | 6 | 13 | 3 |
| 문서8 | 2 | 12 | 10 | 10 | 0 | 1 | 5 | 8 |
| 문서9 | 14 | 14 | 0 | 5 | 11 | 6 | 0 | 3 |
보통 내가 가진 문서를 믄서-단어 행렬로 놓는 게 자연어 처리 및 분석, 텍스트 마이닝의 진정한 시작점이 된다.
scikit-learn으로 문서-단어 행렬 만들기
파이썬 머신러닝 라이브러리 scikit-learn에서 CountVectorizer라는 걸 활용하면 아주 쉽게 처리할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
from sklearn.feature_extraction.text import CountVectorizer
training_documents = ["Five fantastic fish flew off to find faraway functions.", "Maybe find another five fantastic fish?", "Find my fish with a function please!"]
test_text = ["Another five fish find another faraway fish."]
bow_vectorizer = CountVectorizer()
bow_vectorizer.fit(training_documents)
bow_vector = bow_vectorizer.transform(test_text)
print(bow_vector.toarray())
# [[2 0 1 1 2 1 0 0 0 0 0 0 0 0 0]]
fit()은 단어 사전을 만드는(학습하는) 거고, 그 다음 transform()를 하면 단어 사전을 기반으로 문서를 벡터화해서 문서-단어 행렬을 만들어준다.
TF-IDF
그런데 문서가 여러개 있을 때 단순히 단어 빈도(Term Frequency)를 적용해서 문서-단어 행렬을 나타내면 문제가 있을 수도 있다.
예를 들어 네이버에서 “머신러닝” 관련 기사들을 모아서 각 기사에서 주로 나타나는 키워드가 무엇인지 뽑는 과제를 수행한다고 해보자. 뭐 일단은 문서-단어 행렬을 만들고 시작할 거다. 그런데 모든 문서에서 머신러닝과 인공지능, AI 등의 단어들만 압도적으로 많이 등장하기 때문에 이런 단어들만 키워드로 뽑히고 정작 개별 문서의 특징을 알 수 있는 희소한 단어들의 중요성을 무시하는 결과가 나올 거다.
결국 어떤 단어가 하나의 문서에서도 많이 사용되었다고 하더라도, 다른 모든 문서에서 널리 쓰이는 흔해 빠진 단어라면 이 단어는 특정성(specificity)이 떨어지는 것이다.
그래서 단순 단어 빈도로 접근하는 게 아니라, 어떤 단어가 한 문서에서 많이 나타난 동시에 다른 문서에서는 잘 나타나지 않는 것까지 고려하기 위한 개념이 등장하는 데 이게 바로 TF-IDF(Term Frequency-Inverse Document Frequency)다. (계산 방법까지 알고 싶다면 위키피디아를 참고하자.)
아무튼 TF-IDF는 단순한 단어 빈도가 아니라 일종의 가중치를 적용한 개념이라고 이해하면 된다. 그래서 이 TF-IDF를 활용해서 문서-단어 행렬을 만들고 분석을 하는 경우도 매우 많다.
그래서 파이썬 라이브러리 scikit-learn에서는 아예 단순 빈도로 접근하는 CountVectorizer말고, TF-IDF로 접근하는 TfidfVectorizer 클래스를 제공하기도 한다.
BoW의 한계와 n-gram
Bow는 말뭉치를 그냥 가방 안에 다 쑤셔 넣어서 단어 개수만 꺼내서 살피는 방식이기 때문에 단어의 순서를 무시한다. 이게 바로 Bow의 가장 큰 문제점 혹은 한계다. (애초에 이런 작전으로 설계된 거라서 한계라고 하긴 좀 그렇긴 한데… 아무튼.)
그래서 등장하는 개념이 있으니 바로 n-gram이다.
예를 들어 “이 음식은 너무 맛있다”라는 문서가 있을 때 전통적인 Bow로 접근하면 각 단어(feature)는 “이”, “음식은”, “너무”, “맛있다”가 될 거다. 그러나 ngram은 단어를 n개씩 묶어서 그걸 하나의 feature로 보는 거다. 그래서 만약 2개씩 묶은 bigram 모델을 사용하면 “이 음식은”, “음식은 너무”, “너무 맛있다”가 된다.
Bow는 각 단어를 독립적으로 고려하지만 이렇게 bigram, trigram과 같은 모델을 적용하면 단어가 나타나는 순서라든지 가까운 단어들을 함께 고려하게 되는 셈이라 때에 따라 더 적절한 방법이 되기도 한다.
아무튼 BoW
아무리 ngram 모델을 적용하더라도 Bow 모델은 그 빈도만 세기 때문에 맥락을 충분히 고려해야 하는 상황, 즉 텍스트를 생성한다거나 예측하는 등의 장면에는 활용이 어렵다.
게다가 학습된 단어 사전을 기반으로 하기 때문에 사전에 없는 새로운 단어가 나타났을 때 그걸 처리할 방법이 없다. 학습 데이터에 지나치게 의존하기 때문에 오버피팅(overfitting)이 발생하는 거다. 사실 통계적 언어 모델에서 이 오버피팅이 나타나는 건 당연한 것이긴 한데… 아무튼 문제는 문제다.
smoothing(평탄화)라는 방법을 통해 이 문제를 나름대로 어떻게든 해결하는 전략이 있긴 하다. 이미 알고 있는 단어들의 확률을 가지고 알려지지 않은 단어의 확률을 추정(?)하는 방식인데, 일단 너무 깊게 들어가진 말자.
어쨌든 Bag-of-Words는 이런저런 한계가 존재함에도 불구하고, 비교적 훌륭한 성능을 보여주고 활용도가 높기 때문에 여전히 주류로 사용되고 있다.
일단 Bag-of-Words에 대한 설명은 여기까지.