파이썬 형태소분석기 '바른'을 활용한 텍스트 분석 – (5) 토픽 모델링
한국어 형태소 분석기 바른으로 형태소 분석 수행 후에 토픽 모델링을 해보는 코드 예시.
토픽 모델링이란
보통 하나의 문서는 여러 가지 토픽(주제)을 동시에 포함하고 있기 때문에 다양한 분류가 가능하다. 예를 들어, 파이썬 언어로 웹 응용 프로그램을 구현하는 내용의 문서가 있다고 한다면, 이 파이썬 관련 문서들과 묶일 수도 있고 웹 응용프로그램 관련 문서들과 엮일 수도 있다.
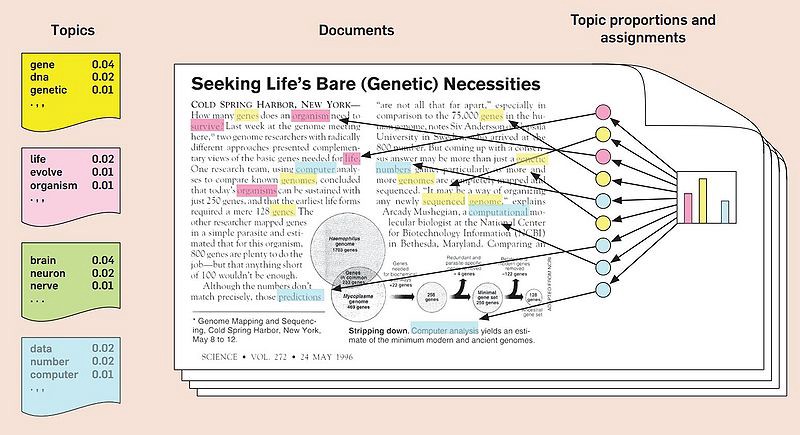
이와 같은 상황에서 유용한 기법이 토픽 모델링이다. 토픽 모델링은 문서들을 완전히 분리된 집단으로 나누는 것이 아니라 문서들과 몇 개의 토픽(주제)들을 연계하기 때문이다. 물론 이 토픽들은 문서들로부터 학습된 결과로 자동 생성된다. 이 때 각 문서의 특성에 따라 각 토픽과의 연계 정도, 혹은 중요도가 다르게 매겨진다. 그래서 토픽 모델링을 통해 우리는 문서 집합 내에 포함된 주요 주제, 혹은 정리된 개념들을 추출할 수 있다.
토픽 모델링에서는 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)이라는 확률 모형을 많이 사용하는데, 깊게 들어가면 어려워서 나도 잘 모르니까 본 포스팅에서 자세한 설명은 생략한다. 궁금하면 위키피디아 읽고 공부하자.
어쨌든 이번에는 파이썬을 활용하여 토픽 모델링을 수행하는 코드 예시.
형태소 분석
pandas 데이터프레임 형식에서 바로 형태소 분석. 형태소 분석 적용할 때는 람다 함수를 활용했다.
1
2
3
4
5
6
7
8
9
from bareunpy import Tagger
import pandas as pd
tagger = Tagger(API_KEY, 'localhost')
df = pd.read_excel('rawdata.xlsx')
morph_analysis = lambda x: tagger.tags([x]).pos() if type(x) is str else None
df['형태소분석결과'] = df['원문'].apply(morph_analysis)
토픽 모델링
1) 문서 준비
우선 공백으로 연결된 문서 형식으로 변환해서 넣어줘야 하기 때문에, 데이터를 준비하자.
1
2
3
4
5
6
7
8
9
10
11
from sklearn.feature_extraction.text import TfidfVectorizer
# 벡터화
vectorizer = TfidfVectorizer(tokenizer=str.split,
binary=True,
use_idf=True,
norm=None,
ngram_range=(1,1),
max_features=1000)
문서단어행렬 = vectorizer.fit_transform(df["문서"])
2) 문서-단어 행렬 생성
문서-단어 행렬 형식으로 벡터화가 필요하다. TfidfVectorizer를 사용한다.
1
2
3
4
5
6
7
8
9
10
11
from sklearn.feature_extraction.text import TfidfVectorizer
'''벡터화'''
vectorizer = TfidfVectorizer(tokenizer=str.split,
binary=True,
use_idf=True,
norm=None,
ngram_range=(1,2),
max_features=3000)
문서단어행렬 = vectorizer.fit_transform(df["문서"])
만약 이런저런 파라미터를 조정하고 싶다면 TfidfVectorizer()를 수행할 때 넣어주면 된다. (예를 들어 TF-IDF를 사용하고 싶지 않다면, use_idf 파라미터를 조정해줄 수 있다.)
벡터화 과정에서 생성에 사용한 단어와 모든 문서에서 등장한 빈도를 확인해보자.
1
2
3
4
# 각 단어의 등장 빈도 확인
vocabulary = vectorizer.vocabulary_
vocabulary = {k: int(v) for k, v in vocabulary.items()}
print(vocabulary)
벡터화에 사용된 단어들은 따로 리스트로 저장하자. (추후 군집화 결과를 출력할 때 활용한다.)
1
2
3
4
# 전체 단어 리스트 저장 (추후 토픽모델링 결과 출력에 활용)
전체단어리스트 = vectorizer.get_feature_names_out()
print(f"어휘 개수: {len(전체단어리스트)}")
print(전체단어리스트[:10])
문서-단어 행렬을 확인해보자.
1
2
# 문서-단어 행렬 확인
pd.DataFrame(문서단어행렬.toarray(), columns=전체단어리스트)
3) LDA 토픽 모델링
토픽 모델링은 sklearn의 LatentDirichletAllocation을 사용한다.
1
2
3
4
5
from sklearn.decomposition import LatentDirichletAllocation
토픽개수 = 10
lda = LatentDirichletAllocation(n_components=토픽개수, random_state=0)
lda.fit(문서단어행렬)
토픽의 개수에 정답은 없다. 데이터의 상태나 토픽 모델링 결과를 보고 알아서 판단해야 한다.
각 토픽들의 주요 어휘를 확인해보자.
1
2
3
4
5
6
# 각 토픽의 주요 어휘 확인
어휘개수 = 10
for 토픽번호, 토픽 in enumerate(lda.components_):
print(f"Topic #{토픽번호}")
print(" ".join([전체단어리스트[i] for i in 토픽.argsort()[:-어휘개수 - 1:-1]]))
print()
4) 토픽모델링을 활용한 문서 분류
토픽 모델링을 수행하고 나면, 각 문서가 어떤 토픽에 가까운지 확률을 돌려주기 때문에 이를 바탕으로 문서 분류도 가능하다.
각 문서의 토픽별 확률을 확인해보고,
1
2
3
# 각 문서에 대해 토픽 확률 추정
토픽별확률 = lda.transform(문서단어행렬)
토픽별확률
가장 높은 확률로 분류를 해서 확인해보자.
1
2
3
4
# 각 문서에 확률이 가장 높은 토픽 할당
df['토픽'] = 토픽별확률.argmax(axis=1)
# 파일로 저장
df[["원문", '토픽']].to_excel("./output/토픽모델링 분류결과.xlsx")
어쨌든 오늘 포스팅은 여기까지.