데이터 과학에서 흔히 일어나는 통계적 역설 Top 3
데이터 과학에서는 관찰 편향과 하위집단에서 나타나는 차이 때문에 통계적 역설이 발생한다. 그리고 이러한 역설을 무시하면 분석의 결론이 완전히 망가질 수 있다. 이 글에서는 데이터 과학에서 가장 널리 나타나는 나타나는 통계적 역설(오류) 세 가지를 살펴본다.
원문 Top 3 Statistical Paradoxes in Data Science 를 읽고 최대한 쉽게 번역해서 남기는 포스팅.
Berkson’s Paradox (벅슨의 역설)
COVID-19 심각도와 흡연 사이에 부적 상관이 발표된 사례(Wenzel 2020)가 있다. 그런데 최근 Nature에 게재된 Griffith 2020에서는 이 결과가 Berkson’s Paradox(벅슨의 역설)라고도 불리는 Collider Bias라고 지적했다.
차트를 보자.
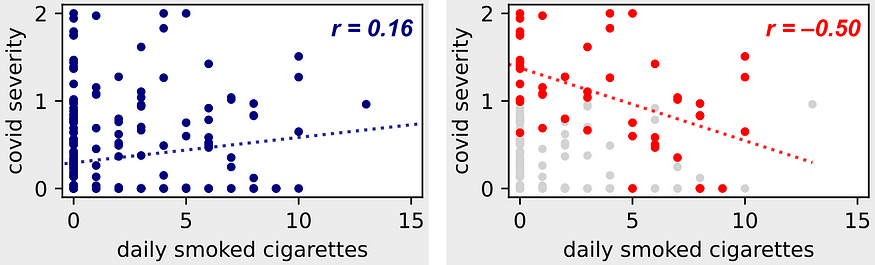
왼쪽 그림은 전체 모집단의 관찰 결과를 담고 있지만, 오른쪽 그림에서는 입원한 사람들만 하이라이트를 해본 것.
왼쪽 그림에서는 COVID-19 심각도와 흡연 담배 사이의 양의 상관 관계를 관찰할 수 있다. 흡연이 호흡기 질환의 위험 요소라는 것을 알고 있으니 이게 상식적인 결과다. 그런데 오른쪽 그림처럼 입원한 사람들의 데이터만 관찰하면 흡연과 COVID-19의 관계가 반전되는 게 보인다.
흡연과 COVID-19 모두 “입원 여부”와 양의 상관이 있기 때문에 여기서 상충(collider)하여 왜곡, 역설이 발생하는 것.
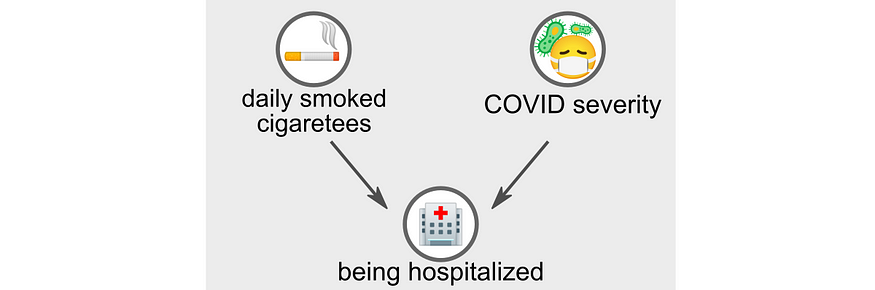
이러한 역설은 당뇨가 담낭염의 위험 인자임에도 불구하고 병원 환자에서 담낭염과 당뇨병 사이에서 음의 상관관계를 발견한 Berkson 1946의 발표와 유사하다.
Latent Variable (잠재 변수)
잠재 변수도 두 변수 사이에서 반전된 상관 관계를 만들어내는 원인이 되기 때문에 주의를 해야 한다.
예를 들어 화재를 진압하기 위해 배치된 소방관의 수와 화재로 인한 부상자 수 사이의 관계를 떠올려보자.
상식적으로는 소방관이 많을수록 부상자가 줄어들기를 기대하지만 집계 데이터에서는 오히려 양의 상관 관계가 나오는 이상한 현상(Brooks의 법칙 참조)이 발생할 수가 있다. 이 경우 소방관이 많이 배치될수록 부상자 수도 많다는 이상한 결론을 내리게 될 거다. 이건 “화재 심각도”라는 잠재변수를 간과했기 때문이다. (심각한 화재일수록 더 많은 부상을 초래하는 경향이 있으며, 자연히 더 많은 소방관을 투입해야 한다.)
차트로 보자.
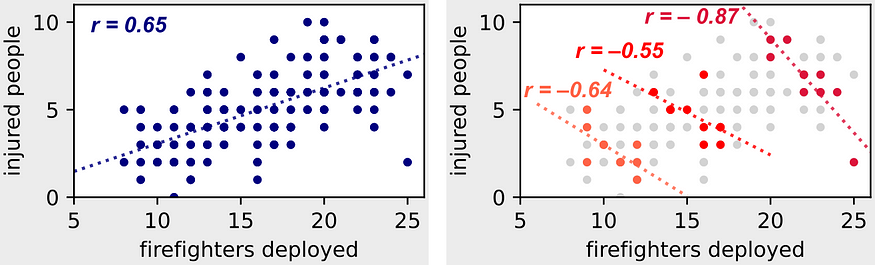
왼쪽 그림은 모든 종류의 화재에 대한 관측 값을 집계한 반면, 오른쪽 그림은 화재 심각도가 관찰된 경우 이를 3단계로 나눠본 거다.
이렇게 잠재 변수 “화재 심각도”를 조건으로 걸어놓고 그룹을 나누어 살펴보면, 배치된 소방관 수와 부상자 수는 확실한 음의 상관 관계를 보인다. 비로소 소방관을 더 많이 배치할수록 부상자가 적다는 상식적인 결론을 내릴 수 있게 된 거다.
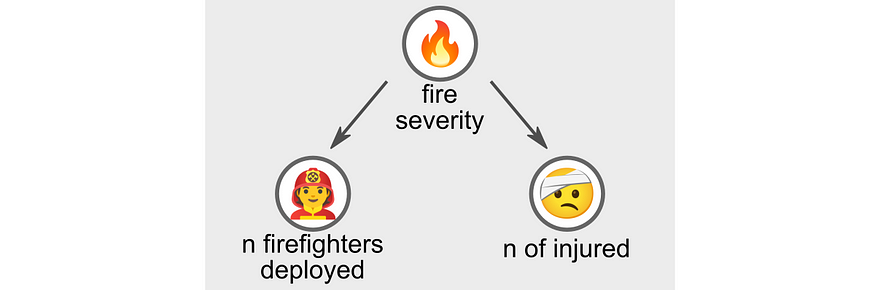
“화재 심각도”는 “소방관 수”와 “부상자 수” 모두에 대해 양의 상관 관계를 갖는 잠재 변수다.
데이터 분석할 때 이렇게 핵심적인 잠재 변수를 간과하면 안 된다는 교훈.
Simpson’s Paradox (심슨의 역설)
Simpson ‘s Paradox는 하위 그룹으로 나눴을 때 일관되게 관찰되는 경향성이 그 그룹들을 병합했을 때 반전되는 현상이다. (하위 그룹의 클래스 불균형)
이 역설의 악명이 높아진 건 캘리포니아 대학 합격률에서 성차별의 증거를 찾기 위한 분석(Bickel 1975)에서 발견되었다. 모든 각 학과에서 여성 지원자가 남성 지원자보다 합격률이 더 높은데, 전체로 집계하면 여성 지원자가 남성 지원자보다 합격률이 낮게 나타난 거다.
이게 어떻게 가능한지 알아보자.
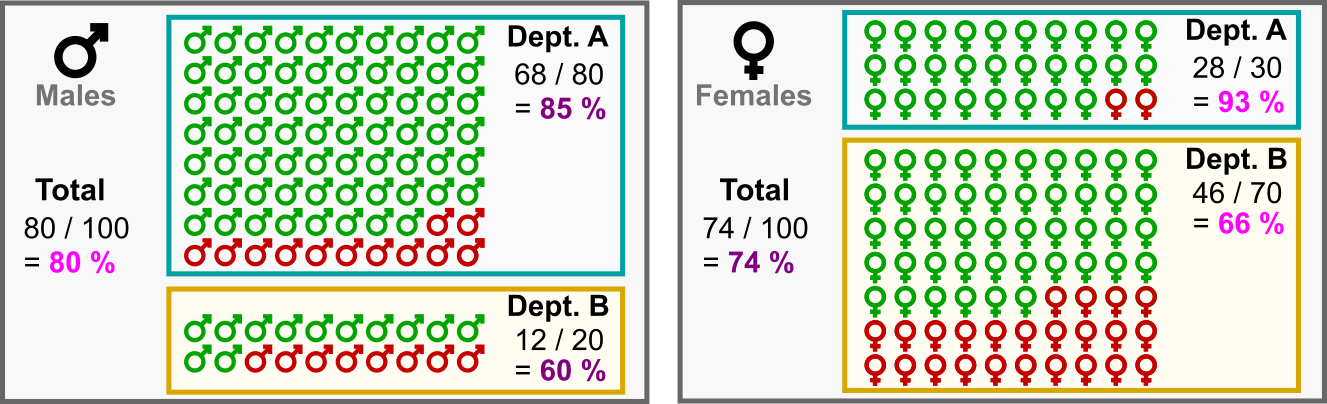
- 남자 전체 100 명
- A학과에 80명 지원하여 68명 합격 (합격률 85%)
- B학과에 20명 지원하여 12명 합격 (합격률 60%)
- 여성 전체 100 명
- A학과에 30명 지원하여 28명 합격 (합격률 93%)
- B학과에 70명 지원하여 46명 합격 (합격률 66%)
실제로 대부분의 여성 지원자들은 더 경쟁이 심한 B학과에 지원한 반면, 대부분의 남성 지원자들은 경쟁이 덜한 A학과에 지원한 걸 알 수 있다. 두 학과의 지원자 성별에서 이미 상당한 불균형이 있었고, 이게 모순의 원인이다.
결론
상충 변수(collider), 잠재 변수, 클래스 불균형은 데이터 과학에서 통계적 역설을 야기할 수 있다. 데이터를 분석할 때 이러한 핵심 개념들을 간과하지 말자.