파이썬으로 구조방정식 통계 분석하기
통계 돌릴 때 SPSS 안 쓴지 몇 년이 지났다. 최근에 파이썬으로 구조방정식 돌릴 방법을 찾다가 쉽게 사용법을 소개하는 괜찮은 글이 있어서 이 기회에 블로그에 남겨놓고자 한다.
아래 내용은 Towards Data Science에 기고된 Structural Equation Modeling 글의 번역이다.
- 구조방정식이란
- 구조방정식은 언제 사용해야 할까
- 구조방정식의 유형
- 구조방정식 모델링 예시
- 구조방정식 다이어그램(시각화)
- 구조방정식 분석 도구
- 구조방정식 파이썬 코드 예시 (결과 해석 포함)
구조방정식이란
구조방정식 모델(SEM: Structural Equation Modeling)은 “측정 변수(또는 관측 변수)”와 “잠재 변수”의 관계, 그리고 “잠재변수” 간의 관계를 설명하는 모델이다.
그리고 여기서 “잠재 변수”란 우리가 개념적으로는 이해하고 있지만 직접 측정할 수는 없는 변수를 의미한다. 예를 들면 지능 같은 것. 지능을 측정하는 도구로 시험, IQ 테스트를 비롯한 여러 검사들을 사용하지만, 이 모든 검사들이 결국엔 문제를 통해 점수를 측정한 후, 그 점수로 지능을 추정하고 있을 뿐이기 때문이다.
따라서 측정된 변수(시험 점수)를 잠재변수(지능)로 변환하는 모델이 필요하고, 구조방정식 모델링이 바로 이러한 관계를 가장 잘 추정할 수 있는 훌륭한 도구다.
구조방정식은 언제 사용해야 할까
구조방정식을 사용하기 위해서는 몇가지 고려사항이 필요하다.
- “측정 변수”와 “잠재 변수”에 대한 개념이 있어야 한다. 구조방정식 모델링의 목표는 측정된 변수와 잠재 변수 간의 관계, 그리고 여러 잠재 변수 간의 관계를 모델링하는 것이기 때문에 중요하지만 측정할 수 없는 개념, 즉 “잠재 변수”가 무엇인지 정의할 수 있어야 한다.
- 구조방정식 모델링은 주로 확인 및 테스트 방법으로 활용된다. 그래서 일단 염두에 두고 있는 변수 간 관계에 대한 가설을 정의하는 것으로 모델링 단계를 시작한다. 예를 들어 지능에 대한 모델을 만들고 싶다면 지능에 영향을 미칠 수 있는 다양한 측정 변수 및 잠재 변수를 식별하는 것부터 시작해야 한다는 뜻이다.
- 따라서 구조방정식 모델링은 탐색적 도구로는 적합하지 않다. 변수 간 관계가 어떻게 연결될 것인지 파악이 안될 때는 차라리 잠재 변수를 탐색하기 위해 만들어진 다른 기법을 사용하는 것이 더 낫다. 탐색적 요인 분석(EFA: Exploratory Factor Analysis)은 훌륭한 대안이다.
- 구조 방정식 모델은 잠재적인 현상에 영향을 미치는 여러 개념들에 대한 이해를 돕는다는 측면에서 분석 목적으로는 매우 유용하다. 하지만 구조 방정식 모델이 항상 예측 성능 측면에서 우수한 것은 아니다. 이해와 해석이 아닌 예측 성능만을 고려한다면 구조 방정식 모델링은 잘못된 선택일 수 있다.
- 구조 방정식 모델은 변수 간의 가설 관계를 기반으로 계수 추정치를 제공한다. 즉, 사용자가 지정한 관계 이외의 다른 관계는 찾을 수 없다. 그래서 여러가지 가설적 모델을 설계한 다음 그 차이를 분석하여 더 나은 모델을 선택해야 한다.
구조방정식의 유형
구조방정식의 공식적인(?) 정의에 따르면 다양한 모델을 구조 방정식 모델링의 유형으로 인정해야 한다. 예를 들어 다음과 같은 것들을 모두 구조방정식 모델링으로 볼 수 있다.
- Confirmatory Factor Analysis (확인적 요인 분석)
- Confirmatory Composite Analysis
- Path Analysis (경로 분석)
- Partial Least Squares Path Modeling
- Latent Growth modeling
이 글에서 굳이 위 모델들의 차이까지 다루진 않겠다.
어쨌든 중요한 건 “측정 변수”, “잠재 변수”, 그리고 이 변수들 간의 가설적 관계다.
구조방정식 모델링 예시
예시로 회사에서의 직무 성과에 대한 구조방정식 모델링을 해보자.
직무 성과는 직접 측정이 불가능하기 때문에 “잠재 변수”로 사용해야 한다.
이제 3개의 “측정 변수”를 기반으로 직무 성과을 추정한다고 가정해보자.
- 잠재 변수 “직무 성과”
ClientSat: 주요 고객의 만족도 점수 (1~100점)SuperSat: 상사의 성과 평가 점수 (1~100점)ProjCompl: 성공적으로 수행한 프로젝트의 비율 (%)
그리고 이러한 직무 성과는 사회성, 지적 능력, 동기라는 3개의 잠재 변수에 의해 영향을 받는다는 가설에서 시작하자.
이 잠재 변수들도 직접 측정할 수 없기 때문에 각각의 측정 변수를 정의해야 한다.
- 잠재 변수 “사회성”
PsychTest1: 성격검사 결과 (1~100점)PsychTest2: 성격검사 결과 (1~100점)
- 잠재 변수 “지적 능력”
YrsEdu: 고등 교육을 받은 햇수IQ: IQ 테스트 점수
- 잠재 변수 “동기”
HrsTrain: 교육에 참여한 시간HrsWrk: 주당 평균 근무 시간
이제 가설을 바탕으로 다이어그램을 그려볼 차례다.
구조방정식 다이어그램(시각화)
구조방정식 모델은 여러 방향으로 계수들이 포함되기 때문에 전체 모델을 다이어그램으로 이해하게 쉽게 표현할 수 있어야 한다.
구조방정식 다이어그램을 그릴 때는 몇 가지 관행을 따른다.
- 잠재 변수는 원으로 표현
- 측정 변수는 사각형으로 표현
- 변수 간 관계는 화살표로 표현
- 분산(Variances) 및 잔차(Residuals)는 변수 자체의 되돌이 화살표로 표현
이 글에서 사용한 예시를 다이어그램으로 표현하면 다음과 같이 그릴 수 있다.
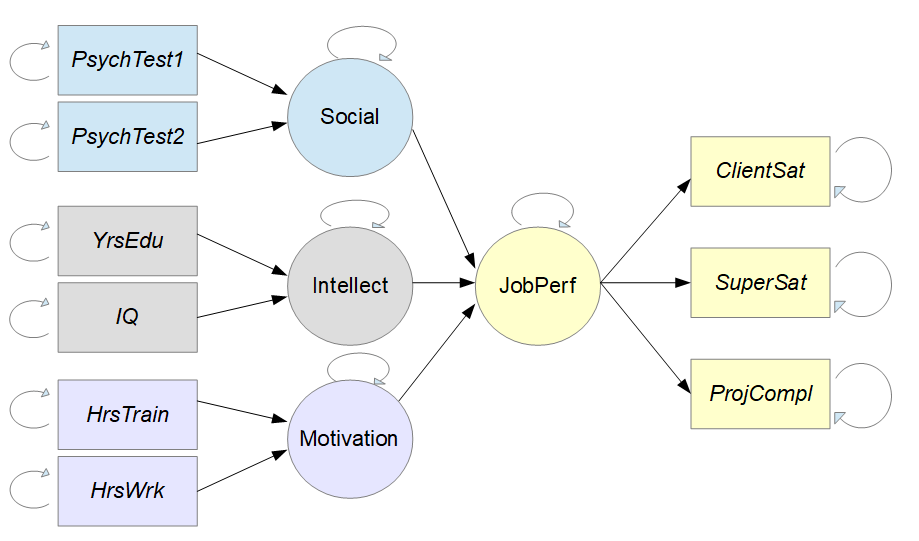
이렇게 다이어그램으로 구조방정식 모델링을 표현할 수 있다면 각 화살표의 계수(coefficients)와 표준오차(standard errors) 추정을 통해 변수 간의 관계를 정량화하는 것이 분석 목표가 된다.
구조방정식 분석 도구
구조 방정식 모델을 피팅하려면 다이어그램의 각 화살표마다 하나씩 상당히 많은 계수를 추정해야 하기 때문에 통계 관련 프로그램, 패키지를 써야 한다.
대표적으로 다음과 같은 것들이 있다,
- LISREL
- Amos
- MPlus
- Stata 또는 SPSS
- R 패키지
sem,lavaan,OpenMx,LISREL,EQS,Mplus - Python 패키지
semopy
구조 방정식 모델링은 어떤 알고리즘을 사용해야 하는지 정해진 표준이 없고, 소프트웨어 패키지마다 조금씩 결과값이 다르게 나오기도 한다. 그래도 대부분 변수 측면에서는 동일한 결론을 내리기 때문에 큰 문제가 되지 않는다.
이는 많은 고급 모델링 기법에서 발생하는 현상이기 때문에 그냥 마음 편히 자신에게 편리한 도구를 쓰고 분석 결과를 보고할 때는 어떤 소프트웨어를 사용했는지 명시하기만 하면 된다.
구조방정식 파이썬 코드 예시 (결과 해석 포함)
이번 분석에 사용할 파이썬 패키지는 pandas, semopy. 미리 설치를 해두자.
그리고 사용할 데이터는 여기에서.
일단 데이터 읽어오고,
1
2
3
4
import pandas as pd
import semopy
data = pd.read_csv('./StructuralEquationModelingData.csv')
이제 구조방정식 모델의 문법에 따라 적어줘야 하는데, 파이썬 패키지 semopy에서 사용하는 구조방정식 모델 문법은 R 패키지 lavaan에서 사용하는 것과 거의 똑같다. 일단 대표적인 다음과 같다. 더 자세히 알고 싶다면 공식문서를 읽어보자.
- 잠재 변수를 정의할 때는
=~기호 사용
잠재변수1 =~ 측정변수1 + 측정변수2 - 잠재 변수를 다른 잠재 변수로 회귀시킬 때는
~기호 사용
잠재변수1 ~ 잠재변수2 + 잠재변수3 - 분산 및 공분산 (측정 변수 중 일부에 잠재 변수로 표현되지 않는 상관 관계가 있을 것으로 예상되는 경우)
측정변수1 ~~ 측정변수2
아무튼 아래와 같이 구조방정식 모델을 문법에 따라 적어주고, fit 메서드를 사용하면 끝.
1
2
3
4
5
6
7
8
9
10
11
12
13
model_spec = """
# measurement model
JobPerf =~ ClientSat + SuperSat + ProjCompl
Social =~ PsychTest1 + PsychTest2
Intellect =~ YrsEdu + IQ
Motivation =~ HrsTrn + HrsWrk
# regressions
JobPerf ~ Social + Intellect + Motivation
"""
model = semopy.Model(model_spec)
result = model.fit(data)
print(result)
이제 결과를 확인해보자. (결과표가 가로로 나오길래 .T를 사용해서 세로로 돌려 출력했다.)
1
2
stats = semopy.calc_stats(model)
print(stats.T)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Value
DoF 21.000000
DoF Baseline 36.000000
chi2 3590.241343
chi2 p-value 0.000000
chi2 Baseline 10295.641357
CFI 0.652109
GFI 0.651285
AGFI 0.402203
NFI 0.651285
TLI 0.403615
RMSEA 0.412473
AIC 40.819517
BIC 158.605644
LogLik 3.590241
1) 구조방정식 모델의 카이제곱 검증
일단 가장 먼저 살펴봐야할 값은 chi2 p-value, 즉 카이제곱 검정의 유의성이다. 이 검증 결과는 모델이 데이터 변화의 중요한 부분을 충분히 설명하는지 p값을 통해 확인할 수 있다. 일반적으로 p값이 0.05 미만이어야 유의미한 것으로 간주되기 때문에, 일단 이 예시의 경우 모델이 잘 작동하고 있다고 결론을 내릴 수 있다.
그 외에도 CFI, GFI, TLI, RMSEA와 같은 모델 적합도 관련 지표가 나오는데 여기서 이 얘기까지 다루진 않겠다. (더 궁금하면 “구조방정식 모델 적합도” 관련 검색어로 구글링 해보기.)
2) 구조 방정식 모델의 회귀 계수
이제 각 변수들 간의 회귀 계수를 살펴보자.
1
2
estimates = model.inspect()
print(estimates)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
lval op rval Estimate Std. Err z-value p-value
0 JobPerf ~ Social 5.269493e-01 0.04741 11.114673 0.0
1 JobPerf ~ Intellect 1.039498e+00 0.11494 9.043845 0.0
2 JobPerf ~ Motivation 2.963975e+00 0.248955 11.905683 0.0
3 ClientSat ~ JobPerf 1.000000e+00 - - -
4 SuperSat ~ JobPerf 2.503557e+00 0.20307 12.328518 0.0
5 ProjCompl ~ JobPerf 2.559049e+00 0.213706 11.974633 0.0
6 PsychTest1 ~ Social 1.000000e+00 - - -
7 PsychTest2 ~ Social 2.340379e+00 0.094641 24.728967 0.0
8 YrsEdu ~ Intellect 1.000000e+00 - - -
9 IQ ~ Intellect 4.673359e+00 0.4939 9.462147 0.0
10 HrsTrn ~ Motivation 1.000000e+00 - - -
11 HrsWrk ~ Motivation 1.187368e+01 0.270784 43.849243 0.0
12 JobPerf ~~ JobPerf 0.000000e+00 0.283172 0.0 1.0
13 Motivation ~~ Motivation 4.108837e+00 0.260571 15.768604 0.0
14 Motivation ~~ Social -8.750834e-01 0.413852 -2.114483 0.034474
15 Motivation ~~ Intellect 2.173391e-02 0.051045 0.425777 0.67027
16 Social ~~ Social 4.109617e+01 3.676237 11.178867 0.0
17 Social ~~ Intellect -2.198703e-02 0.16127 -0.136337 0.891555
18 Intellect ~~ Intellect 6.326920e-01 0.098257 6.439177 0.0
19 YrsEdu ~~ YrsEdu 2.309057e+00 0.116934 19.746661 0.0
20 ProjCompl ~~ ProjCompl 1.277574e+02 5.816961 21.962909 0.0
21 PsychTest1 ~~ PsychTest1 5.982018e+01 2.731358 21.901258 0.0
22 IQ ~~ IQ 0.000000e+00 1.19825 0.0 1.0
23 PsychTest2 ~~ PsychTest2 5.305417e-15 3.017083 0.0 1.0
24 SuperSat ~~ SuperSat 9.568801e+00 1.12964 8.470663 0.0
25 ClientSat ~~ ClientSat 2.982786e+02 13.340469 22.358932 0.0
26 HrsWrk ~~ HrsWrk 0.000000e+00 2.560481 0.0 1.0
27 HrsTrn ~~ HrsTrn 2.056676e+00 0.093753 21.937118 0.0
세 가지 잠재 변수인 Social(사회성), Intellect(지적 능력), Motivation(동기)가 JobPerf(직무 성과)에 어떤 영향을 미치는지 알아보는 것이 목표이기 때문에 0~2행을 보면 된다. 우선 맨 오른쪽 p-value가 모두 0.05보다 작기 때문에, 이 3개의 잠재변수가 종속 잠재변수 JobPerf에 영향을 미친다고 결론을 내릴 수 있다.
각 잠재변수가 직무 성과에 얼마나 영향을 미치는지 더 자세히 알아보려면 Estimate(회귀계수 추정치)를 확인하면 된다. 참고로 e+, e- 뒤에 숫자가 붙은 것은 소수점을 위아래로 이동해서 표현한다는 의미. 아무튼 계수가 높은 것부터 나열하면 다음과 같다.
- Motivation(동기) : 2.964
- Intellect(지적 능력) : 1.039
- Social(사회성) : 0.527
동기의 변화가 직무 성과에 가장 큰 영향을 미친다는 것을 의미하고, 그 다음 지능이 미치는 영향이 두 번째로 높으며, 사회성은 직무성과에 영향은 미치지만 동기와 지적 능력에 비해는 영향력이 낮다고 해석할 수 있다.
만약 현재 이 구조방정식 모델을 시각화 해서 저장하고 싶다면 다음과 같이 코드를 작성해줄 수 있다.
1
semopy.semplot(model, "./output.png")
게다가 semopy 패키지는 아예 HTML 형식의 리포트 자동 생성 기능까지 제공하고 있더라. (공식 문서 참고)
1
semopy.report(model, "./report")
아무튼 이렇게 파이썬으로 구조방정식 돌리기 실습 끝.